정의
시계열(time series) 데이터는 관측치가 시간적 순서를 가진 데이터이다. 이 데이터는 변수간의 상관성(correation)이 존재하는 데이터를 다루며, i.i.d, 연속(continous)하거나 불규칙적(irregular)데이터는 다루기 않는다.
시계열 데이터는 과거의 데이터를 통해서 현재의 움직임 그리고 미래를 예측하는데 사용된다. 일반적인 label데이터는 input과 label간의 상관관계를 다루는 반면에 시간에 따라 어떻게 움직이는 과거의 자료를 가지고 예측하게 된다.
데이터
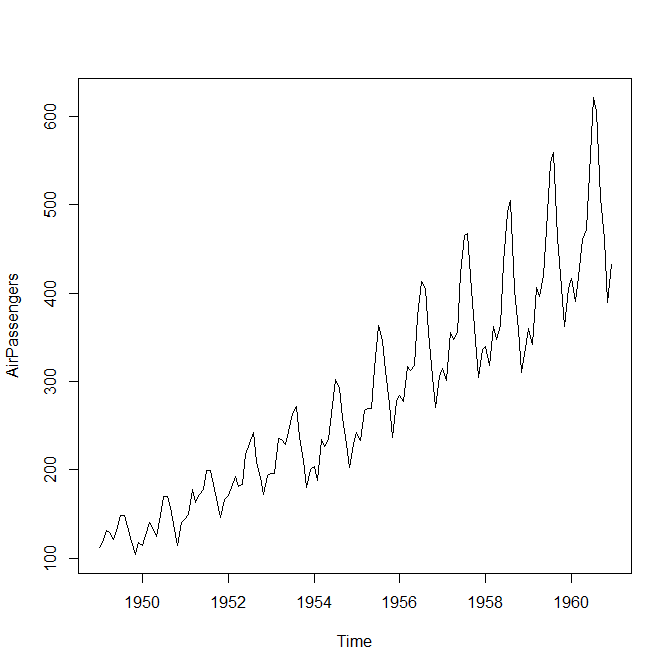
옆의 데이터는 AirPassengers라는 데이터로 R에 기본적으로 내장되어있는 데이터이다. x축은 Time이고, Y축은 고객의 수를 의미하는 것으로 볼 수 있다. 여기서 label 데이터처럼 시간과 고객의 수 관계를 확인해보려는 것이 아니라 과거의 특정 시간(구간)의 데이터를 통해 미래를 예측한다.
그래서 시계열을 통해 추세(Trend), 계절성(seanality), 랜덤(random) 데이터 등 을 분석하고 앞으로 어떻게 될 것인지 예측해 볼 수 있다.

추세(Trend) : 추세라는 것은 말 그대로 경향을 의미한다. 세부적인 데이터를 다 빼고 전체적으로 보았을 때 주식이 감소하는지 증가하는지 대략적인정보를 보여준다.
계절성(Seasonality) : 특정한 기간마다 어떤 패턴을 가지고 반복하는지 확인 할 수 있는 특성이다. 이 데이터를 통해 앞으로 어떻게 변화할 것인지 예측할 수 있다.
랜덤(Random) : 노이즈(noise)라고도 불리는 이 데이터는 추세, 계절성 등으로 설명되지 않은 데이터를 의미한다. 이러한 데이터를 가지고 예측하게 된다면 예측의 오차가 커지기 때문에 전처리를 통해서 최대한 예측하는데 관여하지 않도록 하는 것이 중요하다.
댓글