IDEA
BERT의 주요 네트워크로 사용되고 있는 Attention Trasformer이다. 논문 저자는 기존 RNN베이스 모델에 대해서 많은 회의감을 느끼는 것 같다. 그렇다면 이 논문에서 RNN의 어떤 점을 안좋게 보았으며, RNN의 단점을 어떻게 보완했을까?
- RNN의 단점
- RNN의 구조를 보면 하나의 직렬로 이루어진 Network이다. 그래서 병렬처리가 되지 않는다.
- RNN은 오래 전에 학습된 데이터에 대해서는 유추하기 어렵다.
- long term dependencies
- RNN은 한방향에 대해서 밖에 유추 할 수 없다.
- Attention Trasformer의 장점
- 병렬처리가 가능하다.
- RNN처럼 직전의 input을 보는 유추하는 것이 아닌 전체 데이터에서 가장 가능성이 높은 것을 선택한다.
- 2번의 이유로 유추의 범위가 넓어지고 양방향 유추가 가능해진다.
LSTM vs Transformer
LSTM은 조건부 확률을 다루고 Transformer는 i.i.d를 다룬다. 아래 그림을 예시로 A라는 단어 다음에 나오는 확률분포를 생각해보자.
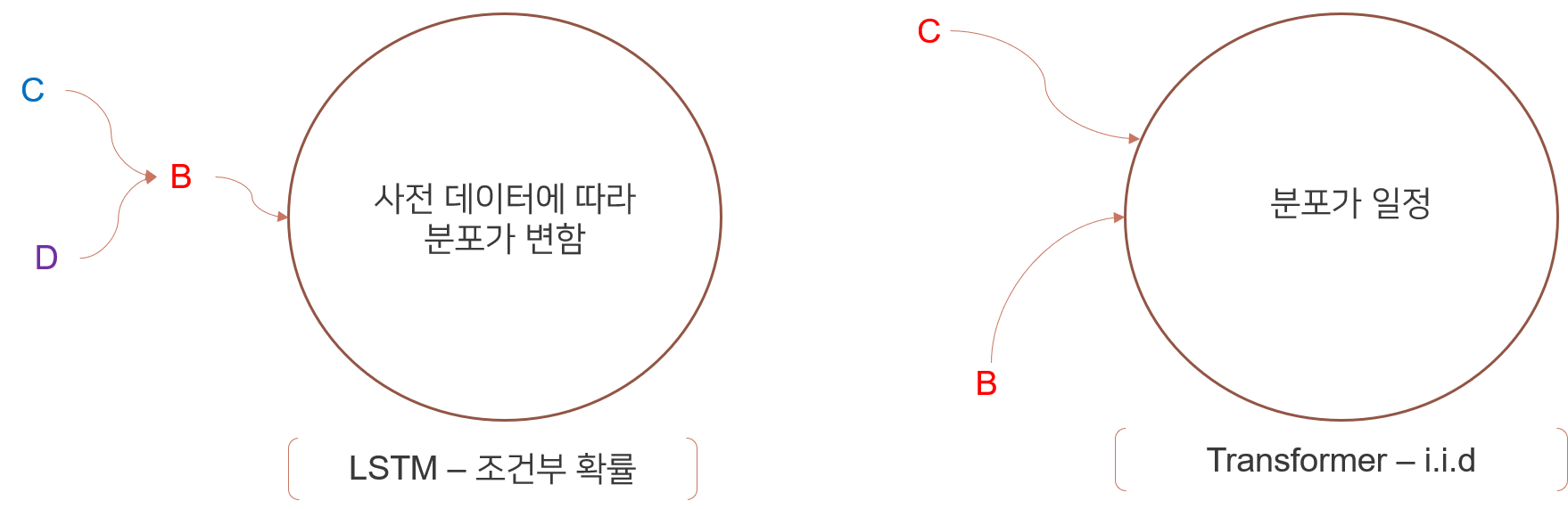
LSTM의 관점에서는 단어 A가 나오는 이전 단어에 의해 A이후 단어의 확률분포가 달라지게 된다. 그래서 공식을 보면 확률과 통계 책에서 많이 봐왔던 조건부 확률을 의미하는 공식이 나온다. $$P(x_{t} | x_{0} x_{1} ... x_{t-1})$$ 그렇기 때문에 IDEA부분에서 말한 것 처럼 데이터의 순서를 중요하게 생각하기 때문에 병렬처리를 할 수 없다.
Transformer는 i.i.d분포를 가진다. 즉, 각 단어에 다음 나올 확률이 이전 단어에 영향을 받지 독립적으로 동일하면서 자기만의 분포를 가진다. 아래 공식은 Multi-head Attention에 나오는 공식이다. $$ softmax(\frac {Q K^{T}} {\sqrt{d_{t}}})V $$ 위에 나오는 모든 공식의 데이터(Q,K,V)는 같은 데이터는 쓰이며 Multi-head Attention layer에 들어가기 전에 이미 embedding이 된 상태이다. 그렇다면 위의 공식이 왜 i.i.d를 가르키는지 알아보자. 딥러닝에서 데이터간의 상관도를 보기위해 가장 많이 사용하는 것 중 하나는 $\cos(\theta)$ 이다.
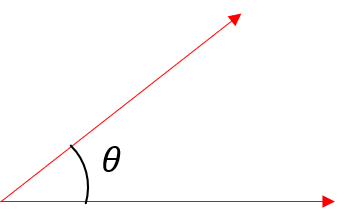
위의 그림처럼 $Q K^{T}$ 를 하게 된다면 각 단어 벡터에 대한 자기 상관을 구할 수 있게 된다. $softmax$를 통해 확률 분포를 구하게 되고, 다시 한번 $V$를 matrix multiply를 하므로 각 단어 벡터에 대한 상관도를 강조할 수 있게 된다. 왜냐하면 결국 어떤 단어와 주변들의 embedding을 한 상태이기 때문이다. 그래서 마지막 V를 곱하므로 단어 벡터의 상관도를 더욱 더 강조할 수 있게 된다.
Transformer에 사용되는 각 layer 살펴보기
Transformer는 Encoder와 Decoder로 나누어져 있다. Decoder부분에는 Masked Multi-Head Attention위에 Multi-Head Attention이 하나 더 있다.
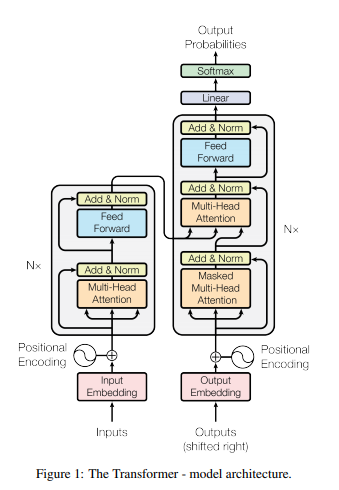
아래 그림은 Transformer에 사용되는 layer들을 나타낸 것이다. 생소한 개념인 Positional embedding의 효과 및 의미와 Multi-head Attention 대한 의미는 위에서 설명하였으니 과정에 대해서 간략하게 설명하겠다. Add & Norm layer는 layer들끼리 더했을때 어떤 장점이 있는지에 대해 설명하고 마지막으로 Position-wise Feed-Forward Networks에 대해 설명하겠다.
Positional embedding
Positional embedding의 목적
embedding을 하는 이유는 어떤 단어를 중심으로 주변 단어들의 벡터, 상관도, 고유벡터, 고유 값 등으로 중요도 및 확률 분포를 나타내고 싶기 때문이다. 이 말을 수가 아니라 의미로 풀어보자면 언어는 문법적 요소와 의미적(semantics)요소가 모두 포함되어있어야 한다는 것이다. 그래서 단어의 순서에 대한 position이 굉장히 중요하다. RNN은 순환적 구조로 순서에 맞춰 학습하지만 Transformer architecture는 순환적 구조가 아니기 때문에 단어의 순서와 위치 정보를 알려주어 문법적/의미적 요소를 데이터에 포함해주어야만 한다.
이 정보(peice of information)를 추가하기 위해서 2가지 방법으로 나뉘어질 수 있다.
첫 번째, [0,1]범위 내에서 정보들을 표현하는 방법이다. 하지만 얼마나 많은 정보가 있을지 알 수 없기 때문에 [0,1]범위 내에서 일대일 매칭으로 표현한다는 것은 굉장히 쉽지 않다. 또한, 다른 문장에서 같은 단어라도 문법적 요소와 의미가 달라질 수 있는데 주어진 범위내에서 표현하기는 쉽지 않다.
두 번째, 단어를 정수([1,2,3,...])로 나타내는 것이다. 문장의 길이가 다양한데 데이터 값이 너무 커질수도 있고, 트레이닝에 썻던 데이터보다 더 긴 문장이 들어올 수도 있다. 또, 다양한 길이의 문장은 generalization을 해칠 수 있다.
따라서, 아래의 criteria를 만족시킬 수 있어야한다.
- 단어가 문장에 맞는 unique한 아웃풋을 내놓을 수 있어야 한다.
- 문장 길이에 상관없이 generalization 할 수 있어야 한다.
- 결정적이여야 한다. 즉, 확률적으로 하나의 output만을 뽑을 수 있어야 한다.
Method
Positional embedding은 이 모든 criteria를 만족시킬수 있도록 도와준다. positional embedding의 공식은 아래와 같다.
$$ PE_{(pos,2i)}=\begin{cases}
\text{} sin(pos/10000^{2i/d_{model}}), & \text{if }2i = 2k \\
\text{} cos(pos/10000^{2i/d_{model}}) & \text{if }2i = 2k+1
\end{cases} $$
공식만 봐서는 어떻게 어떻게 정보의 위치를 1대1 매칭하는지 다소 이해하기 어렵다. pos를보다 분모 값이 변할수록 sin과 cos그래프가 어떤식으로 변하는지 아래에 그림을 참고하자!
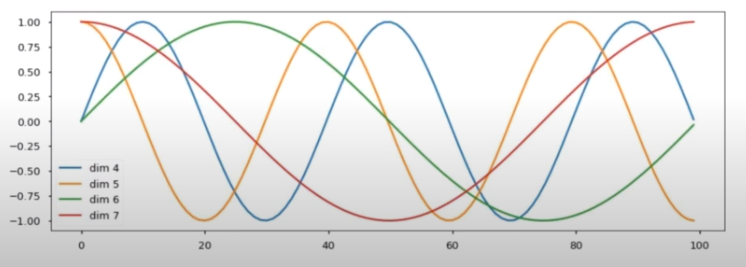
$\sin(\theta)$를 예로 들자면, $\theta = \frac {\pi} {\alpha} + \beta $ 일 때, $\alpha$가 커질수록 파동은 짧아지고 $\beta$에 따라 시작 위치가 달라진다. 따라서 positional embedding은 상당히 많이 다른 파동을 가진다고 볼 수 있어 단어에 대한 벡터를 표현하는 방식도 많아진다.
즉, 하나의 단어의 순서는 경우의 수가 많지만 서로 다르게 embedding되기 때문에 중복을 대폭 줄일 수 있다.
Multi-head Attention
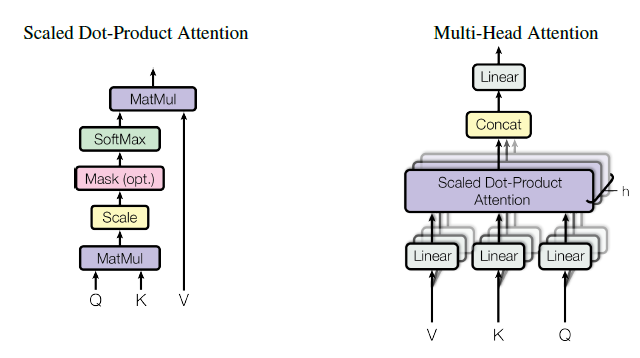
위의 그림은 Multi-head Attention의 구조이다. Linear라고 되어있는 부분은 $ O_{k} = X_{k} * W_{k} + B_{k} $ 을 의미하므로 Scaled Dot product Attention에 중점을 두도록 하겠다. 여러단계로 나뉘어져 있지만, 공식은 아래와 같다.
$$ Attention(Q,K,V) = softmax(\frac{QK^{T}}{\sqrt{d_{k}}})V $$
이 공식을 두고 단계별로 어떻게 계산되어지는지 어떤 의미를 가지게 되는지 확인해보겠다.
- matmul : $ QK^{T} $
- dot product를 한글로하면 내적이다. 두 벡터사이의 내적은 벡터의 $\theta$ 즉, 상관도를 알 수 있게 한다. $\cos(0) = 1$이기 때문에 $\theta$값이 작을수록 큰 값을 가지게 되고 클 수록 작은 값을 가지게 된다. 결국 하나의 단어에 대한 모든 단어(embedding size만큼)의 상관도를 알 수 있게 된다.
- scaled : $ \frac {Q K^{T}} {\sqrt{d_{k}}} $
- nomalization이라고 보면 좋겠다.
- masking
- decoder쪽에서 masking하여 정답을 찾는 용도로 사용된다.
- softmax : $ softmax(\frac{Q K^{T}}{\sqrt{d_{k}}}) $
- softmax는 전체 데이터 셋에서 해당 데이터가 정답일 확률을 나타내준다. softmax를 씀으로써 output이 결정적일 수 있게 된다.
- matmul(softmax, V) : $softmax(\frac{QK^{T}}{\sqrt{d_{k}}})V$
- V도 결국은 Q, K와 똑같이 positional embedding이 된 데이터이므로 상관도가 강한 것은 더 강하게 부각시켜 주며 첫번째 row가 이루는 벡터공간과 단어사이에 상관도를 표현한다.
매트릭스 차원은 어떻게 변화될까?
$$ Q_{model} = d_{qr} * d_{qc} \\
K_{model} = d_{kr} * d_{kc} \\
V_{model} = d_{vr} * d_{vc} \\
단, d_{qr} = d_{kr} = d_{vr}, \ d_{qc} = d_{kc} = d_{vc}$$
위의 가정이다. 우리는 같은 차원의 매트릭스를 넣고 계산하게 될 것이다.
$$ \begin{array}{lcr}
\begin{alignat}{5}
QK^{T} &= d_{qr} * d_{qc} * (d_{kr)} * d_{kc})^{T} \\
&= d_{qr} * d_{qc} * d_{kc} * d_{kr} \\
&= d_{qr} * d_{kr} & d_{qr} = d_{kr} 이므로, \\
QK^{T}V &= d_{qr} * d_{kr} * d_{vr} * d_{vc} \\
&= d_{qr} * d_{vc} & d_{kc} = d_{vc} 이므로,
\end{alignat}
\end{array}
$$
이것으로 input과 output사이의 매트릭스 차원 및 값에 대한 설명이 끝났다.
마지막은 input의 데이터를 하나의 메트릭스로 만들어서 Linear한 신경망 하나를 더 추가한 것이다.
Add & Norm
이 부분도 결국 positional embedding의 결과와 norm으로 인해 상관도를 더 크게하여 상관도 및 postion을 명확하게 하기 위함이다.
Position-wise Feed-Forward Networks
말은 거창하지만, fully connected feed-forward network이다. 아래에 공식을 보면 알겠지만, 단순히 weight, bias를 정의해서 Linear하게 구할수도 있고, CNN(kernel size = 1)을 이용하여 구할 수도 있다고 말한다.
$$ FNN = max(0, xW_{1} + B_{1})W_{2} + B_{2} $$
inner-layer의 차원은 2048로 하였고, input과 output의 dimension은 맞춰주었다고 한다.(논문에서는 512) FNN이 필요한 이유는 multi-head attenion에서 여러가지 문장을 병렬로 처리하여 concat하기 때문이다. 이미지 처리 할 때 FNN을 사용하는 이유를 생각해보면 이해가 쉬울거 같다.
댓글