IDEA
딥러닝은 data를 generalization을 통해서 예측을 하지만, a)비용이 비싸고(expensive), b)사용 가능한 데이터를 구하거나 조작하기가 어렵다.
a)의 이유는 수 많은 데이터뿐 아니라 label데이터의 존재가 있어야 하고, 이것을 연산하기 위한 비용도 많이 크다.
b)는 학습시킬 데이터를 구해야 하는 것 뿐만 아니라 image의 경우 여러각도의 사진이 필요하기도 하다.
또, 새로운 class에 대해서는 예측이 불가능하다.
이 논문에서는 Sinamese Neural Networks를 통해서 a single example만을 통해서 학습시켜 비용을 줄이고(One-shot Image), 새로운 class가 들어오더라도 예측 할 수 있게 해준다.
DataSet
DataSet은 One-shot이라는 이름에 맞게 바꾸어 주어야 한다. 클래스마다 하나의 image를 선정하고 선정된 image에 클래스들을 랜덤하게 선정하여 하나의 Pair로 만들어 준다.
예를들어, Class A중에 하나의 이미지를 선정하고 Class A, B, C ... 중 랜덤으로 class A과 쌍으로 만들고 같은 class라면 label데이터로 0을 사용하고 반대는 1을 사용한다.
Model

2개의 네트워크로 그림에서는 표현하였지만 실제로는 하나의 Network를 통해 Weight를 공유한다. 즉, 한 쌍의 데이터 셋이 같은 네트워크에 들어가게 된다. 하지만 마지막 fully-connected network에서 2개의 Network사이에 distance를 구하고 결국 한개의 output을 뽑아낼 것이다. Output에 들어와 있는 값은 2개 class가 가까울 수록 0으로 수렴하게 될 것이고, 멀 수록 1에 가까워 지게 될 것이다.
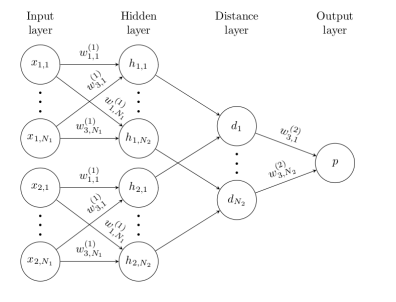
위 그림은 좀 더 간략화 시켜논 것인데 Distance layer를 주목할 필요가 있다. Distance layer이전에는 신경망들이 자신에 속한 network에 연결되어 있지만, Distance layer부터는 2개의 네트워크에서 같은 위치에 해당되는 신경들이 fully connected layer로 가고 있다.
$$ p = \sigma (\sum_{j} \alpha_{j} | h_{1,L-1}^{(j)} - h_{2,L-1}^{(j)}| $$
위에 공식에서 L은 마지막 layer을 가르킨다. L바로 직전 layer 즉, 처음 그림으로 보면 fully connected layer인데 2개의 network사이의 값을 빼주고 output을 한개만 나오게 하기 위해 weight를 매트릭스를 곱해준다. 논문에서 보면 fully conntected layer는 1 * 4096 차원의 매트릭스를 가지는데 weight차원을 4096 * 1구해준다면, 1 * 1차원의 output을 구할 수 있다. 이 값을 sigmoid함수로 확률을 구한다. class가 비슷 할 수록 0에 수렴하게 되고, 다를 수록 1에 수렴하게 될 것이다.
모델을 보면 알겠지만, 마지막 output전에 있는 구조는 얼마든지 바꿀 수 있다. 단순히 weight를 붙이는게 아니라 GAN을 붙인다면 4096개의 데이터의 분포를 맞춰 좀 더 성능이 높아지지 않을까? 라는 생각도 든다. 하나의 output을 뽑는 것이 아니라 GAN을 통해 fully conntected layer간의 같은 분포를 가지도록 학습시키는 것이다. 여기서는 단순히 2네트워크 사이를 빼주기만 했는데, total variation이나 WGAN에 나오는 earth-mover distribution을 사용해도 유효할 것이라는 생각이 든다.
Loss Function
Loss function은 Cross-Entropy loss + L2 regulization을 사용하였다.
$$ L = y\log({p(x)}) + (1-y)\log({1-p(x)}) + \lambda\sum_{j} |w_{j}^{2}| $$
기존 CNN Model과 Siamese Neural Networks의 차이점
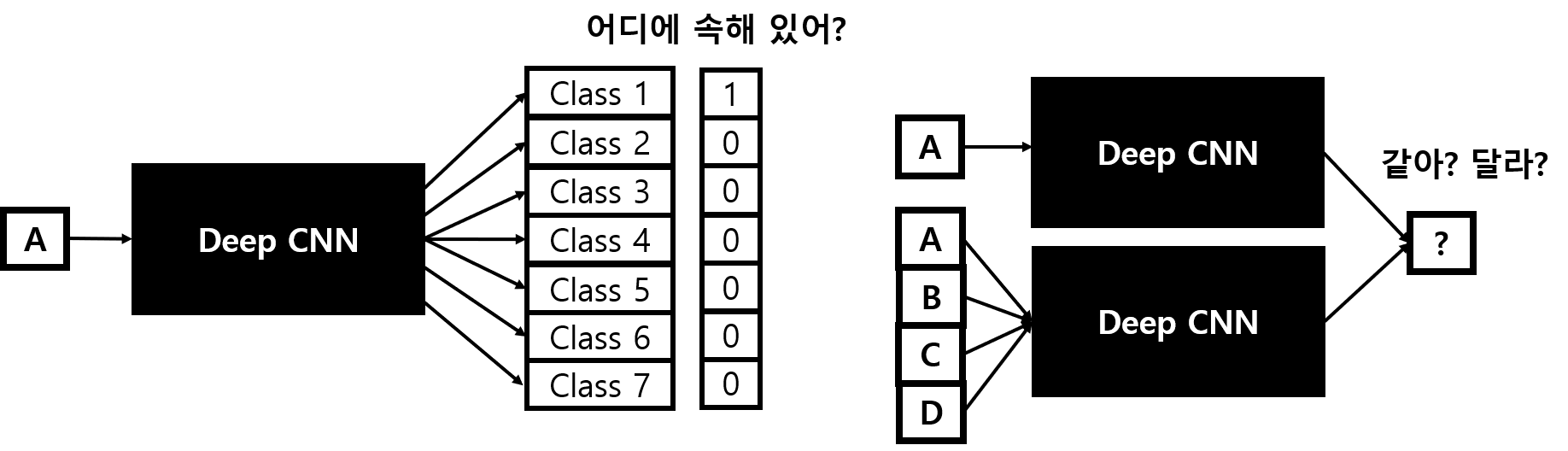
기존 CNN Model은 하나의 이미지가 어디 Class에 속해있는지에 대한 해답을 내놓았다면, Siamese Neural Networks은 2개의 이미지가 같은 그룹에 속해있어? 라는 질문에 대답이 된다. 따라서 기존에 학습되지 않은 object가 들어오더라도 어느 class에 유추할 수 있게된다. 반면에 기존 모델들은 이 object에 관련된 학습된 내용이 없어서 올바르게 유추할 수 있을 것이라고 생각하기 어렵다.
나의 결론
이 논문에서는 기존에 있는 network보다 classification문제를 해결하는데 outperform하다고 하는데 그러기엔 mnist수준의 데이터셋을 가지고 실험을 했다는 것에서 마음이 걸린다. 기본 GAN도 mnist로 학습시키면 실제로는 잘 동작하지만, 다양한 이미지와 rgb벡터를 가진 이미지를 학습하게 되면 이미지를 잘 생성하지 못한다는 문제점을 안고 있다.
'A.I > IMAGE PROCESSING' 카테고리의 다른 글
| Artistic Style Transfer이해하기 (1) | 2019.04.05 |
|---|

댓글